🌐 เอกสารภาษาไทยกำลังจัดทำ — เนื้อหาด้านล่างเป็นภาษาอังกฤษชั่วคราว จนกว่าจะมีการแปล. This page is not yet translated; English content is shown temporarily.
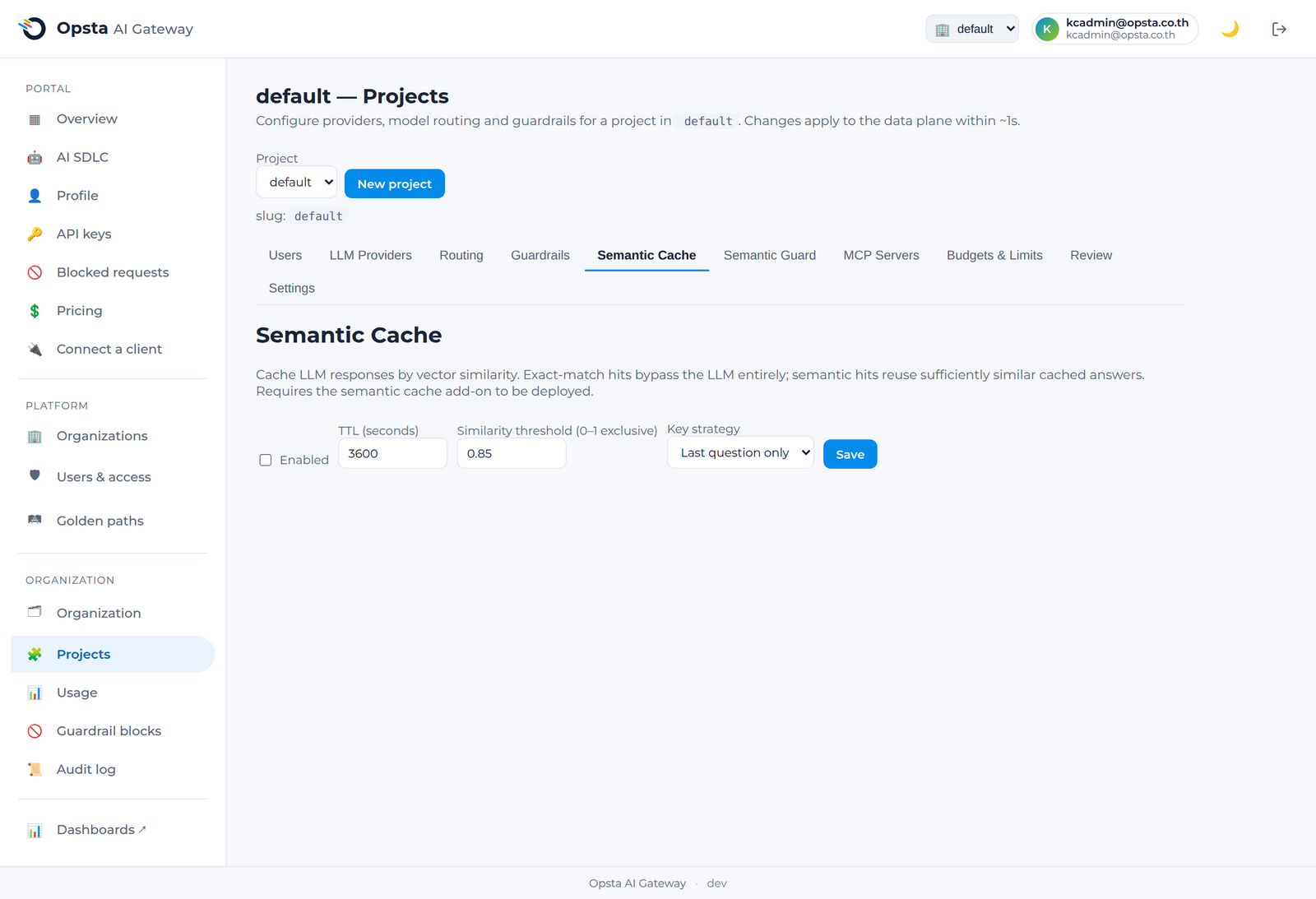
Semantic cache
The semantic cache returns a stored answer when a new prompt is similar in meaning to a previous one, skipping the model call entirely and saving the full token spend. It's per-project, opt-in, and tenant-isolated.
Who can do this
Org admins (for their organization) and platform admins, on Projects → Semantic Cache.
Enable and tune
- Open Projects → Semantic Cache and toggle it on.
- Set the TTL — how long a cached answer stays valid.
- Set the similarity threshold — how close a new prompt must be to a cached one to count as a hit (higher = stricter, fewer but safer hits).
- Choose the key strategy — whether to match on the last question or the full conversation.
- Save.
How it helps
A cache hit short-circuits before the provider, so it costs nothing against the project's budget. Cached responses are isolated per project — one project's answers are never served to another. Savings appear in the project's usage and dashboards.
Tuning the threshold
Start strict (high threshold) and lower it gradually while watching quality. Too low, and unrelated prompts may share an answer; too high, and you get few hits.
Next steps
- Semantic guard — the same vector approach applied to safety.
- Budgets & limits — see cache savings against spend.